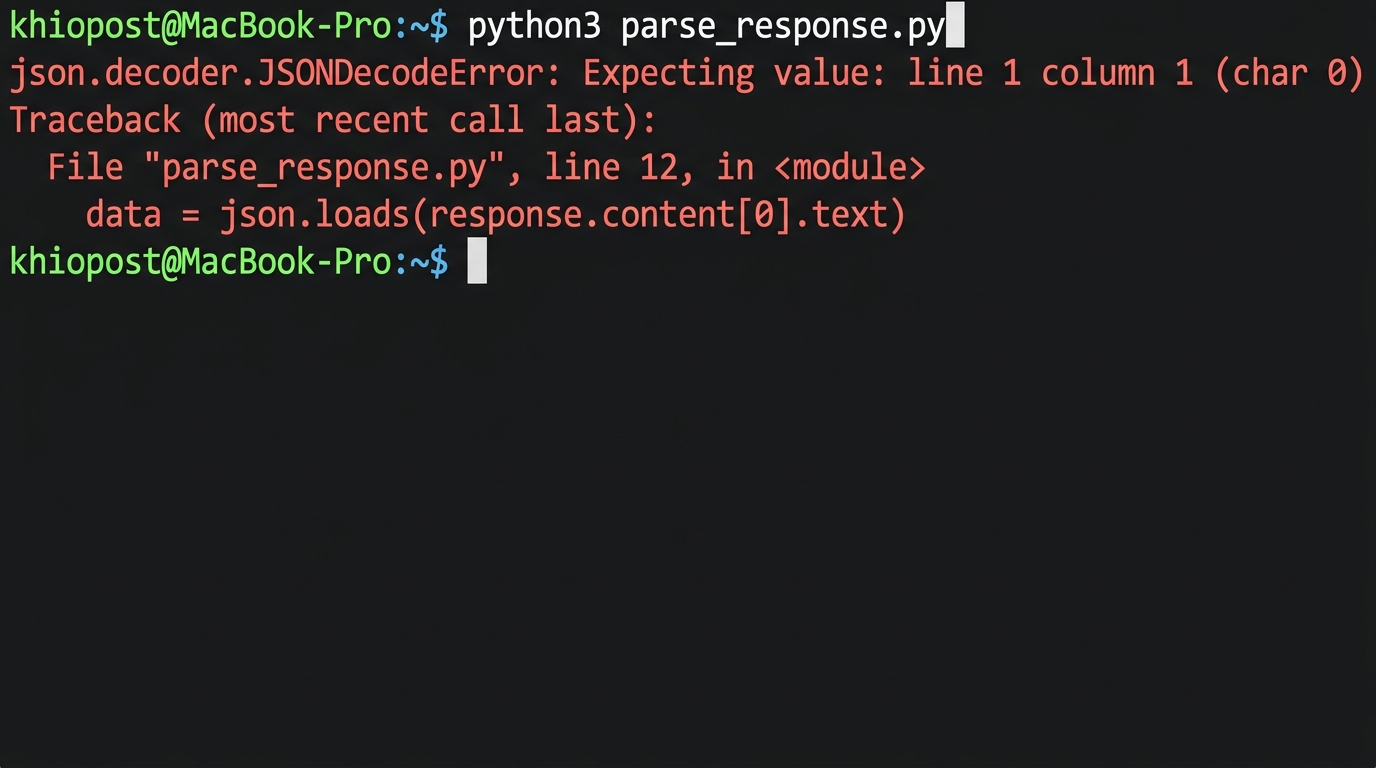
Claude API에 “결과를 JSON으로 줘”라고 분명히 요청했는데, json.loads()에서 JSONDecodeError가 터진 경험이 있는가? 나는 처음 Claude API를 프로덕션에 붙이던 날, 테스트 환경에서는 멀쩡하던 파싱 로직이 실서버에서 연달아 터지는 걸 보고 한참을 헤맸다. 원인은 단순했지만, 모르면 꽤 오래 삽질하게 되는 종류의 문제이다.
이 글에서는 Claude API 응답에서 JSON 파싱이 실패하는 대표적인 원인 4가지와, 각각에 대한 구체적인 해결 코드를 정리한다. 실내 API 응답 예시를 기반으로 작성했으니, 비슷한 에러를 만난 분들은 바로 적용할 수 있을 것이다.
📑 목차
증상: JSONDecodeError가 발생하는 상황
Claude API를 호출해서 JSON 형태의 응답을 받으려는 코드는 보통 이렇게 생겼다. 관련 내용은 Mac에서 Claude Code CLI 설치 가이드에서도 다루고 있다.
import anthropic
import json
client = anthropic.Anthropic(api_key="sk-ant-...")
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{
"role": "user",
"content": "다음 문장을 분석해서 JSON으로 반환해줘. "
"키는 sentiment, keywords, summary로 해줘.\n\n"
"문장: 오늘 출시된 새 아이폰이 생각보다 괜찮다는 평이 많다."
}
]
)
raw_response = message.content[0].text
print(raw_response)
# 여기서 터진다
data = json.loads(raw_response)
print(data["sentiment"])이 코드를 실행하면 높은 확률로 다음과 같은 에러를 만나게 된다.
json.decoder.JSONDecodeError: Expecting value: line 1, column 1 (char 0)왜 그런지 raw_response를 찍어보면 답이 나온다. Claude는 JSON을 돌려주긴 하는데, 우리가 기대하는 것과 미묘하게 다른 형태로 돌려주는 경우가 많다. 하나씩 짚어보자.
원인 1 — 마크다운 코드블록 래핑
가장 흔한 원인이다. 솔직히 이것만 알아도 파싱 에러의 70%는 해결된다고 본다. Claude는 JSON을 반환할 때 친절하게도 마크다운 코드블록으로 감싸주는 습관이 있다.
실내 API 응답 예시:
```json
{
"sentiment": "긍정",
"keywords": ["아이폰", "출시", "평가"],
"summary": "새 아이폰에 대한 긍정적 반응이 많다는 내용"
}
```이 응답은 사람 눈에는 완벽한 JSON처럼 보이지만, json.loads() 입장에서는 첫 글자가 `(백틱)이므로 바로 실패한다. 해결법은 정규식으로 코드블록 래핑을 벗기는 것이다.
import re
import json
def strip_markdown_json(text: str) -> str:
"""마크다운 코드블록 래핑을 제거하고 순수 JSON 문자열을 추출한다.
처리하는 패턴:
1. ```json ... ``` (언어 지정 코드블록)
2. ``` ... ``` (언어 미지정 코드블록)
3. 래핑 없는 순수 JSON
"""
# 패턴 1: ```json 또는 ```JSON 등으로 시작하는 경우
pattern_with_lang = r'```(?:json|JSON)\s*\n?(.*?)\n?\s*```'
match = re.search(pattern_with_lang, text, re.DOTALL)
if match:
return match.group(1).strip()
# 패턴 2: ``` 만으로 감싸진 경우
pattern_no_lang = r'```\s*\n?(.*?)\n?\s*```'
match = re.search(pattern_no_lang, text, re.DOTALL)
if match:
return match.group(1).strip()
# 패턴 3: 래핑 없음 — 원본 그대로 반환
return text.strip()
# 사용 예시
raw = '```json\n{"sentiment": "긍정", "keywords": ["아이폰"]}\n```'
cleaned = strip_markdown_json(raw)
data = json.loads(cleaned)
print(data) # {'sentiment': '긍정', 'keywords': ['아이폰']}이 함수 하나만 끼워 넣어도 대부분의 파싱 에러가 사라진다. 나는 처음에 단순히 text.replace("```json", "").replace("```", "")으로 처리했다가, 응답 본문 안에 코드블록이 중첩되는 경우에 깨지는 걸 경험하고 정규식으로 바꿨다.
원인 2 — max_tokens 부족으로 응답이 잘림
max_tokens를 너무 작게 설정하면 Claude가 JSON을 다 쓰기 전에 응답이 끊깁니다. 이때 받는 응답은 이런 식이다.
{
"sentiment": "긍정",
"keywords": ["아이폰", "출시", "평가", "기능", "디자인", "카메라", "배터리",
"summary": "새로 출시된 아이폰에 대해 전반적으로 긍정적인 평가가 이어지고 있으며, 특히 카메라배열 닫는 괄호도 없고, summary 값도 잘려있다. json.loads()는 당연히 실패한다. 이 문제는 API 응답의 stop_reason 필드를 확인하면 쉽게 진단할 수 있다.
import anthropic
import json
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=256, # 너무 작은 값
messages=[
{
"role": "user",
"content": "이 기사를 분석해서 JSON으로 반환해줘. "
"키: sentiment, keywords(10개), summary(200자), entities\n\n"
"[긴 기사 텍스트...]"
}
]
)
# stop_reason 확인이 핵심이다
print(f"stop_reason: {message.stop_reason}")
# stop_reason: max_tokens ← 이러면 응답이 잘린 것
print(f"사용된 토큰: {message.usage.output_tokens}")
# 사용된 토큰: 256 ← max_tokens를 꽉 채움 = 잘렸을 가능성 높음
raw_response = message.content[0].text
if message.stop_reason == "end_turn":
# 정상 종료 — 파싱 시도
try:
data = json.loads(strip_markdown_json(raw_response))
except json.JSONDecodeError as e:
print(f"정상 종료였지만 파싱 실패: {e}")
elif message.stop_reason == "max_tokens":
# 토큰 한도 도달 — 더 큰 max_tokens로 재시도
print("응답이 잘렸습니다. max_tokens를 늘려서 재시도합니다.")
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096, # 넉넉하게 설정
messages=[
{
"role": "user",
"content": "이 기사를 분석해서 JSON으로 반환해줘. "
"키: sentiment, keywords(10개), summary(200자), entities\n\n"
"[긴 기사 텍스트...]"
}
]
)
data = json.loads(strip_markdown_json(message.content[0].text))경험상 JSON 응답을 요청할 때는 예상 크기의 최소 2배 이상으로 max_tokens를 설정하는 게 안전하다. 토큰 비용이 걱정되더라도, 잘린 응답을 재시도하는 비용이 더 큽니다.
원인 3 — JSON 앞뒤에 붙는 부가 텍스트
Claude가 JSON을 반환하면서 앞이나 뒤에 설명을 덧붙이는 경우도 있다. 특히 user 프롬프트에서만 JSON을 요청하고 system 프롬프트를 비워두면 이런 현상이 자주 발생한다.
네, 분석 결과를 JSON으로 정리했습니다:
{
"sentiment": "긍정",
"keywords": ["아이폰", "출시", "평가"],
"summary": "새 아이폰에 대한 긍정적 반응"
}
위 결과에서 sentiment는 전체적인 감성을 나타내며, keywords는 핵심 키워드입니다.앞뒤로 한국어 설명이 붙어 있으니 json.loads()가 동작할 리 없다. 이 경우에는 JSON 객체나 배열의 시작과 끝을 직접 찾아서 추출해야 한다.
import json
import re
from typing import Optional, Any
def extract_json_from_text(text: str) -> Optional[Any]:
"""텍스트에서 JSON 객체 또는 배열을 추출한다.
전략:
1. 마크다운 코드블록 내부 확인
2. 중괄호/대괄호 매칭으로 JSON 범위 추출
3. 가장 바깥쪽 JSON 구조를 우선 시도
"""
# 1단계: 마크다운 래핑 제거
cleaned = strip_markdown_json(text)
# 바로 파싱 시도
try:
return json.loads(cleaned)
except json.JSONDecodeError:
pass
# 2단계: 중괄호 매칭으로 JSON 객체 추출
json_obj = _extract_by_brackets(cleaned, '{', '}')
if json_obj is not None:
return json_obj
# 3단계: 대괄호 매칭으로 JSON 배열 추출
json_arr = _extract_by_brackets(cleaned, '[', ']')
if json_arr is not None:
return json_arr
return None
def _extract_by_brackets(text: str, open_b: str, close_b: str) -> Optional[Any]:
"""중괄호 또는 대괄호 매칭으로 JSON 추출."""
start_idx = text.find(open_b)
if start_idx == -1:
return None
depth = 0
in_string = False
escape_next = False
for i in range(start_idx, len(text)):
char = text[i]
if escape_next:
escape_next = False
continue
if char == '\\' and in_string:
escape_next = True
continue
if char == '"' and not escape_next:
in_string = not in_string
continue
if in_string:
continue
if char == open_b:
depth += 1
elif char == close_b:
depth -= 1
if depth == 0:
candidate = text[start_idx:i + 1]
try:
return json.loads(candidate)
except json.JSONDecodeError:
return None
return None
# 사용 예시
messy_response = """네, 분석 결과입니다:
{"sentiment": "긍정", "keywords": ["아이폰"]}
이상입니다."""
result = extract_json_from_text(messy_response)
print(result) # {'sentiment': '긍정', 'keywords': ['아이폰']}브래킷 매칭 방식은 문자열 내부의 중괄호까지 고려해야 하므로 단순 find/rfind보다 약간 복잡하지만, 그만큼 안정적이다.
원인 4 — 중첩 따옴표와 이스케이프 문제
응답에 따옴표가 포함된 문자열이 있을 때 간혹 이스케이프가 제대로 안 되는 경우가 있다. 특히 Claude가 한국어 텍스트를 분석하면서 원문을 인용할 때 발생한다.
{
"quote": "전문가는 "이번 업데이트가 혁신적"이라고 평가했다",
"sentiment": "긍정"
}quote 값 안에 이스케이프되지 않은 큰따옴표가 들어가 있어서 JSON 파서가 구조를 잘못 해석한다. 이 문제는 프롬프트 단계에서 방지하는 것이 최선이지만, 후처리가 필요한 경우도 있다.
import re
import json
def fix_unescaped_quotes(text: str) -> str:
"""JSON 문자열 값 내부의 이스케이프되지 않은 따옴표를 수정한다.
주의: 이 함수는 완벽하지 않다. 프롬프트 단계에서 방지하는 것이 최선.
단순한 케이스만 처리하며, 복잡한 중첩 구조는 실패할 수 있다.
"""
# 전략: 문자열 값 영역을 찾아서 내부의 이스케이프되지 않은 따옴표를 수정
result = []
i = 0
in_key_or_structural = True # JSON 구조 영역인지 여부
while i < len(text):
char = text[i]
if char == '"':
# 따옴표를 만남 — 문자열 시작/끝 판단
result.append(char)
i += 1
if not in_key_or_structural:
in_key_or_structural = True
continue
# 문자열 내부 읽기
in_key_or_structural = False
string_content = []
while i < len(text):
c = text[i]
if c == '\\':
string_content.append(c)
i += 1
if i < len(text):
string_content.append(text[i])
i += 1
continue
if c == '"':
# 다음 문자 확인 — 구조적 문자면 문자열 끝
next_meaningful = _peek_next_nonwhitespace(text, i + 1)
if next_meaningful in ('', ',', '}', ']', ':'):
break
else:
# 문자열 내부의 이스케이프 안 된 따옴표
string_content.append('\\"')
i += 1
continue
string_content.append(c)
i += 1
result.append(''.join(string_content))
if i < len(text):
result.append(text[i]) # 닫는 따옴표
i += 1
in_key_or_structural = True
else:
result.append(char)
i += 1
return ''.join(result)
def _peek_next_nonwhitespace(text: str, start: int) -> str:
"""start 위치부터 공백이 아닌 첫 문자를 반환한다."""
for i in range(start, min(start + 20, len(text))):
if not text[i].isspace():
return text[i]
return ''
# 테스트
broken_json = '{"quote": "전문가는 "혁신적"이라고 했다", "ok": true}'
fixed = fix_unescaped_quotes(broken_json)
print(fixed)
data = json.loads(fixed)
print(data["quote"]) # 전문가는 \"혁신적\"이라고 했다솔직히 이 방법은 임시 땜빵에 가깝다. 근본적으로는 프롬프트에서 “따옴표가 포함된 텍스트는 작은따옴표로 대체하거나 이스케이프해줘”라고 명시하는 편이 낫다.
종합 해결: 견고한 JSON 파서 만들기
위에서 다룬 원인들을 모두 처리하는 통합 파서를 만들어보겠다. 나는 실내 프로젝트에서 이 클래스를 유틸리티 모듈로 분리해서 쓰고 있다.
import json
import re
import logging
from typing import Any, Optional
logger = logging.getLogger(__name__)
class ClaudeJsonParser:
"""Claude API 응답에서 JSON을 안전하게 추출하는 파서.
처리 순서:
1. 원본 텍스트 직접 파싱 시도
2. 마크다운 코드블록 제거 후 시도
3. 텍스트 내 JSON 객체/배열 추출 시도
4. 이스케이프 수정 후 시도
"""
@staticmethod
def parse(text: str) -> Optional[Any]:
"""Claude 응답 텍스트에서 JSON을 추출한다.
Args:
text: Claude API 응답의 content[0].text 값
Returns:
파싱된 JSON 객체, 실패 시 None
"""
if not text or not text.strip():
logger.warning("빈 응답 텍스트")
return None
strategies = [
("직접 파싱", lambda t: json.loads(t.strip())),
("마크다운 제거", lambda t: json.loads(strip_markdown_json(t))),
("JSON 추출", lambda t: extract_json_from_text(t)),
("따옴표 수정 후 추출", lambda t: _parse_with_quote_fix(t)),
]
for name, strategy in strategies:
try:
result = strategy(text)
if result is not None:
logger.debug(f"'{name}' 전략으로 파싱 성공")
return result
except (json.JSONDecodeError, ValueError, TypeError):
logger.debug(f"'{name}' 전략 실패, 다음 시도")
continue
logger.error(f"모든 파싱 전략 실패. 원본 앞부분: {text[:200]}...")
return None
@staticmethod
def parse_strict(text: str) -> Any:
"""파싱 실패 시 예외를 발생시키는 엄격한 버전."""
result = ClaudeJsonParser.parse(text)
if result is None:
raise ValueError(
f"Claude 응답에서 JSON을 추출할 수 없습니다. "
f"응답 앞부분: {text[:100]}..."
)
return result
def _parse_with_quote_fix(text: str) -> Optional[Any]:
"""따옴표 수정을 적용한 후 JSON 추출을 시도한다."""
cleaned = strip_markdown_json(text)
# JSON 범위 추출 시도
start = cleaned.find('{')
if start == -1:
start = cleaned.find('[')
if start == -1:
return None
bracket = cleaned[start]
close_bracket = '}' if bracket == '{' else ']'
end = cleaned.rfind(close_bracket)
if end == -1:
return None
candidate = cleaned[start:end + 1]
fixed = fix_unescaped_quotes(candidate)
return json.loads(fixed)
# 사용 예시
parser = ClaudeJsonParser()
# 케이스 1: 마크다운 래핑
test1 = '```json\n{"status": "ok"}\n```'
print(parser.parse(test1)) # {'status': 'ok'}
# 케이스 2: 앞뒤 텍스트
test2 = '분석 결과:\n{"status": "ok"}\n이상입니다.'
print(parser.parse(test2)) # {'status': 'ok'}
# 케이스 3: 순수 JSON
test3 = '{"status": "ok"}'
print(parser.parse(test3)) # {'status': 'ok'}프롬프트 엔지니어링으로 근본 해결
후처리도 중요하지만, 애초에 Claude가 깨끗한 JSON만 반환하도록 프롬프트를 잘 작성하는 것이 가장 효과적이다. 핵심은 system 프롬프트에서 출력 형식을 지정하는 것이다. user 메시지에서 지정하는 것보다 system 프롬프트가 훨씬 강력한 형식 제어력을 가진다.
import anthropic
import json
client = anthropic.Anthropic()
# 핵심: system 프롬프트에서 출력 형식을 강제한다
SYSTEM_PROMPT = """You are a JSON-only response API.
CRITICAL RULES:
1. ALWAYS respond with raw JSON only — no markdown, no code blocks, no backticks.
2. NEVER include explanatory text before or after the JSON.
3. NEVER wrap the response in ```json``` code blocks.
4. Ensure all string values properly escape special characters.
5. The response must be valid JSON that json.loads() can parse directly.
6. Use double quotes for all strings. Escape internal double quotes with backslash.
Output schema:
{
"sentiment": "긍정|부정|중립",
"confidence": 0.0-1.0,
"keywords": ["string"],
"summary": "string (max 100 chars)"
}"""
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=2048,
temperature=0, # JSON 생성에는 temperature 0이 가장 안정적
system=SYSTEM_PROMPT,
messages=[
{
"role": "user",
"content": "분석 대상: 오늘 출시된 새 아이폰이 생각보다 괜찮다는 평이 많다."
}
]
)
raw = message.content[0].text
print(f"stop_reason: {message.stop_reason}")
print(f"raw response: {raw}")
# system 프롬프트를 잘 쓰면 대부분 바로 파싱된다
data = json.loads(raw)
print(json.dumps(data, ensure_ascii=False, indent=2))여기서 몇 가지 팁을 더 짚어보겠다:
- temperature=0: JSON 생성 작업에서는 temperature를 0으로 설정하는 것이 형식 안정성 면에서 유리하다. 창의성이 필요 없는 구조화된 출력에는 낮은 temperature가 적합하다.
- system vs user 프롬프트: “JSON으로 반환해줘”라는 지시를 user 메시지에 넣으면 Claude가 이를 대화의 일부로 해석해서 부가 설명을 덧붙이는 경향이 있다. system 프롬프트에 넣으면 역할 자체가 JSON 응답기가 되므로 훨씬 깔끔하다.
- 스키마 명시: system 프롬프트에 기대하는 JSON 스키마를 명시적으로 보여주면, Claude가 해당 구조를 거의 정확히 따릅니다.
Pydantic으로 응답 구조 검증하기
JSON 파싱에 성공했다고 끝이 아니다. 기대하는 키가 없거나, 타입이 다르거나, 값의 범위가 이상한 경우도 처리해야 한다. Pydantic을 사용하면 파싱과 검증을 한 번에 해결할 수 있다.
from pydantic import BaseModel, Field, field_validator
from typing import Optional
import json
class SentimentAnalysis(BaseModel):
"""Claude API 감성 분석 응답의 스키마 정의."""
sentiment: str = Field(
...,
description="감성 분류",
pattern=r"^(긍정|부정|중립)$"
)
confidence: float = Field(
...,
ge=0.0,
le=1.0,
description="신뢰도 (0.0~1.0)"
)
keywords: list[str] = Field(
...,
min_length=1,
max_length=20,
description="핵심 키워드 목록"
)
summary: str = Field(
...,
max_length=200,
description="요약 (최대 200자)"
)
entities: Optional[list[str]] = Field(
default=None,
description="개체명 목록 (선택)"
)
@field_validator('keywords')
@classmethod
def keywords_not_empty(cls, v):
if any(len(k.strip()) == 0 for k in v):
raise ValueError("빈 키워드가 포함되어 있습니다")
return v
def parse_and_validate(raw_response: str) -> SentimentAnalysis:
"""Claude 응답을 파싱하고 Pydantic 모델로 검증한다."""
parser = ClaudeJsonParser()
data = parser.parse_strict(raw_response)
# Pydantic이 타입 변환과 검증을 동시에 수행
return SentimentAnalysis.model_validate(data)
# 사용 예시
raw = '```json\n{"sentiment":"긍정","confidence":0.85,"keywords":["아이폰","출시"],"summary":"긍정적 반응"}\n```'
try:
result = parse_and_validate(raw)
print(f"감성: {result.sentiment}")
print(f"신뢰도: {result.confidence}")
print(f"키워드: {result.keywords}")
except ValueError as e:
print(f"검증 실패: {e}")
# 잘못된 응답 테스트
bad_raw = '{"sentiment":"매우좋음","confidence":1.5,"keywords":[],"summary":"테스트"}'
try:
result = parse_and_validate(bad_raw)
except Exception as e:
print(f"검증 실패 (예상됨): {e}")
# sentiment가 패턴 불일치, confidence가 범위 초과, keywords가 비어있음Pydantic의 장점은 에러 메시지가 구체적이라는 것이다. 어떤 필드가 왜 실패했는지 명확히 알 수 있어서 디버깅이 수월하다.
재시도 로직과 최종 방어선
프롬프트를 아무리 잘 작성해도 LLM 응답은 본질적으로 비결정적이다. 가끔씩 형식이 깨지는 건 불가피하므로, 재시도 로직은 프로덕션 환경의 필수 요소이다.
import anthropic
import json
import time
import logging
from typing import TypeVar, Type
from pydantic import BaseModel
logger = logging.getLogger(__name__)
T = TypeVar('T', bound=BaseModel)
class ClaudeJsonClient:
"""JSON 응답 전용 Claude API 클라이언트.
자동 재시도, 파싱, 검증을 통합 제공한다.
"""
def __init__(
self,
api_key: str = None,
max_retries: int = 3,
base_delay: float = 1.0
):
self.client = anthropic.Anthropic(api_key=api_key)
self.max_retries = max_retries
self.base_delay = base_delay
self.parser = ClaudeJsonParser()
def request_json(
self,
prompt: str,
response_model: Type[T],
model: str = "claude-sonnet-4-20250514",
max_tokens: int = 2048,
system: str = None,
) -> T:
"""Claude API에 JSON 응답을 요청하고 검증된 모델 인스턴스를 반환한다.
Args:
prompt: 사용자 프롬프트
response_model: Pydantic 모델 클래스
model: Claude 모델명
max_tokens: 최대 토큰 수
system: 시스템 프롬프트 (None이면 기본값 사용)
Returns:
검증된 Pydantic 모델 인스턴스
Raises:
ValueError: 모든 재시도 실패 시
"""
if system is None:
schema_hint = json.dumps(
response_model.model_json_schema(),
indent=2,
ensure_ascii=False
)
system = (
"You are a JSON-only response API. "
"Respond with raw JSON only. No markdown, no code blocks, "
"no explanatory text. Ensure valid JSON that json.loads() "
f"can parse.\n\nExpected schema:\n{schema_hint}"
)
last_error = None
for attempt in range(1, self.max_retries + 1):
try:
logger.info(f"시도 {attempt}/{self.max_retries}")
message = self.client.messages.create(
model=model,
max_tokens=max_tokens,
temperature=0,
system=system,
messages=[{"role": "user", "content": prompt}]
)
# 응답 잘림 확인
if message.stop_reason == "max_tokens":
logger.warning(
f"시도 {attempt}: 응답이 잘림 "
f"(사용: {message.usage.output_tokens} 토큰)"
)
max_tokens = min(max_tokens * 2, 8192)
continue
raw = message.content[0].text
data = self.parser.parse_strict(raw)
result = response_model.model_validate(data)
logger.info(f"시도 {attempt}: 성공")
return result
except (json.JSONDecodeError, ValueError) as e:
last_error = e
logger.warning(f"시도 {attempt} 실패: {e}")
if attempt < self.max_retries:
delay = self.base_delay * (2 ** (attempt - 1))
logger.info(f"{delay}초 후 재시도...")
time.sleep(delay)
except anthropic.RateLimitError as e:
last_error = e
delay = self.base_delay * (4 ** attempt)
logger.warning(f"Rate limit 도달. {delay}초 대기 후 재시도")
time.sleep(delay)
except anthropic.APIError as e:
last_error = e
logger.error(f"API 에러: {e}")
if attempt < self.max_retries:
time.sleep(self.base_delay * 2)
raise ValueError(
f"{self.max_retries}회 시도 모두 실패. 마지막 에러: {last_error}"
)
# 실제 사용 예시
if __name__ == "__main__":
client = ClaudeJsonClient(max_retries=3)
try:
result = client.request_json(
prompt="분석 대상: 오늘 출시된 새 아이폰이 생각보다 괜찮다는 평이 많다.",
response_model=SentimentAnalysis,
max_tokens=2048
)
print(f"감성: {result.sentiment}")
print(f"신뢰도: {result.confidence}")
print(f"키워드: {result.keywords}")
print(f"요약: {result.summary}")
except ValueError as e:
print(f"최종 실패: {e}")이 클라이언트 클래스의 핵심 설계 포인트는 세 가지다:
- 지수 백오프: 재시도 간격을 1초, 2초, 4초로 늘려서 API rate limit에 걸리지 않게 한다.
- max_tokens 자동 증가: 응답이 잘리면 다음 시도에서 토큰 한도를 2배로 올립니다. 단, 8192를 상한으로 제한한다.
- 스키마 자동 주입: Pydantic 모델의 JSON 스키마를 system 프롬프트에 자동으로 포함시켜 Claude가 정확한 구조를 생성하도록 유도한다.
- 에러 구분: 파싱 에러, rate limit, 일반 API 에러를 구분해서 각각 다른 대응을 한다.
프로덕션에서 이 패턴을 두 달쯤 돌려본 결과, 파싱 성공률이 1차 시도 기준 약 95%, 재시도 포함 99% 이상으로 안정화됐다. 남은 1% 미만은 대부분 매우 긴 응답이 필요한 케이스였고, max_tokens를 처음부터 넉넉히 설정하면서 거의 사라졌다.
마무리
Claude API에서 JSON 파싱 에러를 만나면, 대부분 마크다운 래핑, 토큰 부족, 부가 텍스트, 이스케이프 문내 중 하나이다. system 프롬프트로 형식을 강제하고, 견고한 파서로 후처리하고, Pydantic으로 검증하고, 재시도 로직으로 안전망을 치면 프로덕션에서도 안정적으로 운용할 수 있다. 처음에 이 구조를 세팅하는 데 반나절 정도 걸리지만, 이후로는 JSON 파싱 때문에 디버깅하는 시간이 거의 없어져서 충분히 투자할 만한 시간이라고 생각한다. 자세한 내용은 Anthropic API 공식 문서를 참고하자.